
La mort du crawl, l’éveil des signes, version expliquée
-

- Cet été, je vous ai gratifié d’un billet qui semblait un peu venir d’une dimension parallèle : « La mort du crawl, l’éveil des signes ».
Je vous proposais de vous mettre en situation de rêver d’une tout autre infrastructure de moteur de recherche. Infrastructure intéressante du point de vue de la neutralité du net et ainsi que sur d’autres aspects (bande passante, etc).
Je reconnais y avoir été un peu fort, car ma prose était extrêmement imagée.
C’est promis, on va se rattraper aujourd’hui même.
Cette fois-ci, vous aurez les schémas et plein de dessins à colorier…
Tout devrait bien se passer 😉
Le temps de ce billet, je mets donc provisoirement de côté le langage imagé et je mets de vraies images pour expliquer le concept.
Profitez-en, ça ne durera peut-être pas ;-).
- Avertissement
- Le titre du billet
- Comment fonctionne cette infrastructure
- Vue générale de l’infrastructure
- Ensemble site web + analyseur
- Mise à jour de l’analyse
- Le centre de documentation
- Les moteurs de recherche
- L’internaute
- Et les liens dans tout cela ?
- La place du seo dans un tel système ?
- Conclusion
1) Avertissement
Pour éviter de voir vos esprits partir dans de folles envolées astrales, d’imaginer que, si cette infrastructure ne se fait pas, c’est parce qu’il y a une armée d’extra-terrestres qui nous gouverne et qui ne veut pas que cela se fasse… Non non, cool : ce billet tient de la prospective. Ce n’est pas un projet concret à ce jour, bien que cela vous donne quelques clés sur d’autres sujets qui nous concernent tous…Un tel projet nécessiterait beaucoup de tests en laboratoire (mais vraiment beaucoup). Rien ne dit, qu’après cette R&D, il pourrait être déployé à grande échelle (même s’il est, dans ses grandes lignes, imaginé pour résister justement à cela).
Donc, prenez-le bien comme une vision d’un possible futur dans le meilleur des cas.
Surtout, si vous avez des idées, n’hésitez pas à les partager en commentaires ;-).
2) Le titre du billet
Le titre du billet, « La mort du crawl, l’éveil des signes »…Cela ne vous rappelle rien ?
Il s’agit d’un petit clin d’œil sur deux pièces musicales portant un titre approchant.
La première pièce est de Piotr Ilitch Tchaïkovski.
La deuxième pièce est de Camille Saint-Saëns.
Les deux pièces ont exactement le même titre (si avec cela vous ne trouvez pas !!)
Je vous laisse chercher, mais trouver n’est pas indispensable à la compréhension du billet.
3) Comment fonctionne cette infrastructure
Rappelons qu’ici, on va tenter d’élaborer une infrastructure qui permette :- l’émergence plus facile de nouveaux acteurs de la recherche,
- de diminuer la bande passante globale nécessaire, d’économiser l’énergie,
- d’assurer une forme de neutralité des moteurs vis-à-vis des éditeurs de sites web.
4) Vue générale de l’infrastructure
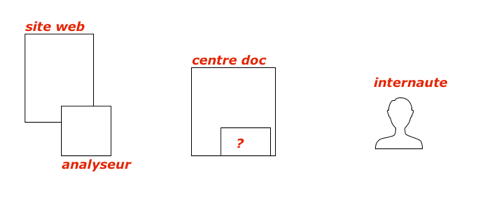
De gauche à droite, nous avons le site web avec, sur le même serveur, un analyseur.
Au centre, nous avons le centre de documentation et une boite mystère…
À droite, l’internaute.
Au centre, nous avons le centre de documentation et une boite mystère…
À droite, l’internaute.
5) Ensemble site web + analyseur
Concentrons-nous sur ce sous-ensemble à gauche sur le croquis.L’analyseur se trouve sur le serveur qui héberge le site. Il se présente comme une sorte de service du serveur. Bien sûr, il est ultra-mega-super sécurisé et incraquable (il suffit de faire un code dissymétrique).
L’éditeur du site n’a rien à faire de particulier autre que de s’occuper de son site, comme d’habitude. L’analyseur se déclenche de façon transparente, sans intervention de l’éditeur du site.
L’analyseur a pour vocation d’élaborer la représentation du site ainsi que de chacune de ses pages.
C’est ici que les représentations du site vont prendre forme.
Mais qu’est-ce qu’une représentation ?
Il s’agit d’objets informatiques qui vont pouvoir être utilisés par les moteurs de recherche. Ces objets permettront aux moteurs de juger ensuite de l’adéquation entre une page/un site et une demande d’un internaute.
À ce stade, pas de jugement. Seulement des « traits de caractère » si on veut.
Il y a au moins trois façons d’élaborer ces objets « représentation », selon l’état de l’art.
a) Ce que l’on sait faire aujourd’hui, une liste de critères plus ou moins précis selon ce que l’on a trouvé sur le site/page.
b) Un écart à un modèle prédéfini détecté (sorte de delta-modeling). Imaginons que l’on réussisse à lister, par exemple, 1000 types de pages « parfaites » pour définir 1000 usages/besoins identifiés et bien choisis. La description d’un seul de ces modèles peut être assez lourde. C’est alors que l’on peut faire entrer en piste le delta qu’a une page par rapport à un des modèles préalablement définis. Il suffirait alors d’envoyer le numéro de référence du modèle et le vecteur « delta par rapport à ce modèle »… Note : je ne peux pas vous dire si cela a déjà été testé, mais je suis sûr qu’il y a des choses très sympas à faire avec cette approche.
c) Par intérêt pour le monde : au lieu de définir une page par rapport à ce qu’elle est, on va la définir par rapport à des profils de recherche identifiés et là, c’est le type d’internaute à un moment t qui compte. On peut aussi faire, avec cette approche, du delta-modeling sur des profils de recherche.
Les résultats de l’analyse sont envoyés (en mode push) au centre de documentation. Plus de crawl ici, c’est le serveur qui prévient le centre de documentation qu’il y a du nouveau et envoie les résultats de l’analyse à celui-ci.
Bien sûr, nouveau site, nouvelle page => nouvelle analyse pour initialiser ce que l’on a.
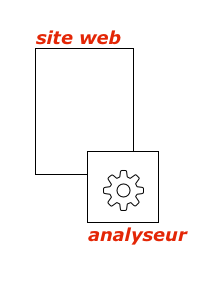
L’analyseur est sur la machine-même où se trouve le site web,
plus besoin de voir les bots venir crawler les pages alors que rien n’a changé
6) Mise à jour de l’analyse
Bon OK, on a notre analyseur, mais comment et quand décide-t-on de refaire une analyse et qu’en fait-on ?Dans mon idée, si rien ne se passe sur le site, l’analyseur ne fait rien.
En cas de modif d’une page, il refait une analyse plus ou moins poussée puis envoie le résultat au centre de documentation seulement si les modifications ne sont pas sans importance (côté analyse).
L’objectif est non seulement d’interdire le crawl via ce système, mais aussi de ne pas envoyer des analyses version n+1 si les différences avec la version n sont infimes.
Prenons un exemple : si on vous dit que quelqu’un est grand (votre recherche) et qu’il mesure 2,087 m. Si, à un moment, on s’aperçoit qu’il ne mesure « que » 2,085 m, cela change-t-il quelque chose au fait qu’il soit grand ?
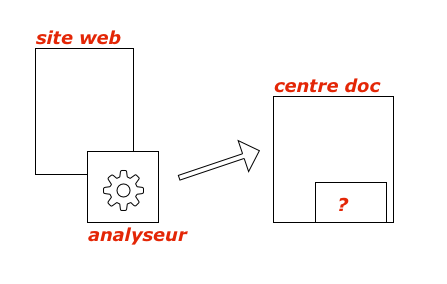
L’analyseur fait signe au centre de documentation via un push,
mais seulement si cela est nécessaire.
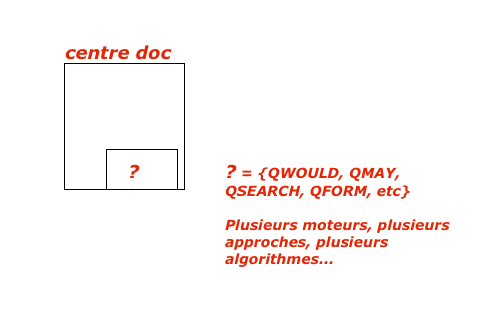
7) Le centre de documentation
Là, c’est la pièce : classification. Pour un SEO, cela est lié au classement dans les SERP.Pourtant ici, cela n’a rien à voir.
Le centre de documentation reçoit les analyses de la part de chacun des sites et les ordonne uniquement pour les mettre en un lieu unique et de façon « arrangée » pour être facile à exploiter pour les moteurs de recherche.
Le centre de documentation ne juge pas. Il décide juste de choisir le meilleur « endroit » où ranger une analyse qu’il vient de recevoir, par exemple.
Le centre de documentation n’est pas la propriété d’un moteur de recherche en particulier, mais plutôt quelque chose de neutre, où chaque moteur peut aller piocher.
C’est un peu compliqué à expliquer, mais il est parfaitement possible de classifier les choses sans les classer 😉
Bien sûr ici, rien que des machines, OK ?
.
.
.
.
.
.
.
.
.
.
.
.
Je vois bien à quoi vous pensez, mais non, ce n’est pas cela 😉
8) Les moteurs de recherche
La ruse est que, si chaque moteur de recherche est bien indépendant, ils sont hébergés sur les serveurs du centre de documentation. Chaque moteur dispose de son espace machine, MAIS chaque moteur a ses propres algos/heuristiques pour « juger » de l’adéquation qu’il peut y avoir entre une demande internaute et des résultats d’analyse à disposition.Pour l’internaute, c’est transparent. Il choisit le moteur qui lui donne le plus de satisfaction et le moteur va aller chercher les meilleures réponses possible avec son propre algo, sans aucune triche, dans le centre de documentation.
Non non, aucune allusion nulle part… 😉
9) L’internaute
L’internaute, c’est comme d’hab, il confie sa vie privée à des sociétés qui les revendent en récompense 🙁 .Je plaisante bien sûr, mais il y a là aussi à gagner, mais là, c’est un autre sujet…
10) Et les liens dans tout cela ?
Ce n’est pas abordé dans ce billet, mais tous les critères actuels et d’autres peuvent être traités. L’idée n’est pas de détruire, mais de construire.Par contre, chacun des moteurs pourra en faire ce qu’il veut…
11) La place du seo dans un tel système ?
Les critères de pertinence sont toujours là, avec d’autres, les clients ont toujours besoin d’être accompagnés ;-).Bon, en même temps, il y a de nombreux leviers que j’imagine pour valoriser les sites et les missions SEO qui ne sont pas encore exploitées…
12) Conclusion
En guise de conclusion, préférez-vous la version avec métaphore ou celle-ci ?Bon, ok, il y a des dessins à colorier, mais est-ce que cela vous a plu ?
Mots-clefs : dessin à colorier, moteurs de recherche, simplissime
Mathieu JANIN
| #
Concernant l’infra technique elle même:
« ultra-mega-super sécurisé et incraquable (il suffit de faire un code dissymétrique). »
Ca, ça n’existe pas.
On découvre des failles dans des codes opensource critiques aprés des décennies de révision par des kadors (cf heartbleed), et même les clés de cryptage les plus sécure sont craquables, tout est question de temps.
Aprés, concernant l’organisation.
Si tu parles de composant fermé pour l’analyseur (je le suppose, mais je ne sais pas ce que tu appelles du code dissymétrique), pas sûr que beaucoup de boites acceptent une saleté de blob propriétaire sur un serveur critique pour leur activité. Sauf bien sûr les inconscient qui utilisent déjà des serveurs windows, bien sûr.
Même si c’était le cas et si certaines acceptaient, un gars arrivera forcément un jour à produire son propre analyseur qui se fera passer pour le composant officiel en émulant son fonctionnement. Ou bien il attaquera le fonctionnement de l’exécutable dans la mémoire de son serveur pour le faire fonctionner différemment. Si ce n’est pas ça, il s’intercalera entre l’indexeur et le centre doc pour injecter les données qu’il souhaite dans la transaction. Il y a trop de points de faiblesse possible si le collecteur des données ne contrôle pas sur place les scores d’agrégat de ce qu’il collecte.
Concernant le moteur, c’est pas franchement plus jouable: tu crois vraiment que google accepterait de financer en commun le coût du centre de documentation avec bing ?
Pour finir, suivant les circonstances où j’aurais ça sous les yeux, je ne sais pas si je préfèrerais le nabla ou le petit delta.
Reply
Christian Méline
| #
Je présente un schéma de principe juste quelque chose d’un peu différent.
C’est comme des classes abstraites si tu veux.
Le reste, c’est de l’implémentation.
Reply
Ludovic
| #
Salut Christian,
J’ai deux remarques :
1) A propos du fonctionnement de cette infrastructure, je ne suis pas sûr que les moteurs se soucient des éditeurs, des internautes à la limite …
Du coup, les moteurs proposeront leur propre algo à délocaliser sur les serveurs éditeurs et favoriseront leurs analyses avec un coefficient comme le … TRUST
2) Je vois que tu étais près à bosser nuit et jour quand tu allais à la fac !
Bravo pour ta studiosité !!!
Reply
Christian Méline
| #
Salut Ludovic,
1) Les moteurs ne se préoccupent pas des éditeurs et pas des internautes (exception faite, peut-être, pour QWant).
Mais en fait, à part leurs bénéfices, de quoi soucient-ils ?
2) oui, la fac… ce n’est pas si vieux… j’y serai bien encore, j’étais très stimulé 😉
Reply
LeMoussel
| #
Je rejoins le commentaire de Mathieu sur l’analyseur. Principe intrusif que celui-ci soit sur la machine-même où se trouve le site web. Cela amene aussi des questions sur les aspetcs sécurité. Vision SEO Hack, l’objectif sera de cracker/simuler l’analyseur ….
Reply
Christian Méline
| #
Qe toutes façons, quoi que l’on fasse, il y a toujours un truc à essayer de craquer 😉
Reply
Christian Méline
| #
Petite précision, cette approche est vaguement comparable, côté risques, à celle qui consiste à monter un kit de paiement électronique sur un serveur.
Mais un avantage énorme à cette méthode : l’analyse peut être beaucoup plus poussée et permettre de balayer le peu de pertinence des moteurs d’aujourd’hui…
Reply
Lionel
| #
Si je peux faire une critique sur le fond, ce serait sur la notion de pertinence.
Tout d’abord, l’intention de recherche est rarement explicite et délimitée.
Le moteur ne sait pas précisément ce que je recherche. C’est pourquoi dans sa SERP Google panache des résultats de nature différente, du marchand, de l’image, de l’actu, du local… sans parler des polysémies.
Mais l’internaute aussi ne sait pas précisément ce qu’il recherche, dans le sens qu’il ne sait pas ce qu’il peut trouver. Si je recherche « grenade » sur Google, je recherche peut-être des infos pour partir à Granada en Espagne, mais peut-être que les informations sur l’île de la Grenade dans les Caraïbes va m’intéresser aussi.
Cette remarque est également valable pour l’angle éditorial des contenus. Peut-être vais-je m’intéresser à une page qui décrit de manière encyclopédique Granada. Mais je serais aussi intéressé par la page qui présente la ville sous un angle humoristique, parodique, et qui de fait semblera moins proche du canon à un algo.
A mon sens, le « pertinent » est aussi variable que le « beau ». Il n’y a pas de règle unique. C’est pourquoi Google panache ses résultats.
Reply
Christian Méline
| #
Chacun des moteurs « embarqués » peut panacher s’il le souhaite.
Tu peux aussi avoir des moteur plus verticaux, etc.
Reply
Victor
| #
J’arrive après la bataille, mais niveau infrastructure c’est plus ou moins Blockchain que tu décris, non? 😉
Reply
Christian Méline
| #
En tous les cas, je ne m’en suis pas inspiré !
Reply