
Réaliser un cocon sémantique avec les metamots
-

- Billet très important ce jour tant attendu par certains :
Non seulement j’explique davantage ce que sont les metamots, mais j’explique aussi comment je fais pour construire des cocons sémantiques grâce aux metamots .
Le programme est donc chargé.
Tous les fichiers qui ont servi ici sont disponibles en téléchargement. C’est mon cadeau pour la nouvelle année.
Après quelques explications sur les metamots, je passe à une de ses utilisations.
J’ai un mot-clé, je veux être visible dessus, je veux donc faire le meilleur cocon possible.
Comment dois-je faire ?
Pour illustrer la méthode, on va prendre, avec son accord, le blog d’un petit jeune qui débute tant en SEO (!) qu’en VTT : Laurent Bourrelly. Son blog VTT.
Comme Laurent est un winner dans l’âme, il veut être prem’s sur « VTT », rien que cela ! Notez que Laurent ne m’a passé que le terme « VTT », rien d’autre, à moi de me débrouiller.
1) C’est quoi les metamots déjà ?
Au départ, vous avez quelques requêtes associées à quelques pages existantes ou à construire.L’objectif est d’aller insérer d’autres lexies dans votre contenu afin de qualifier le contenu de votre page.
Les lexies à insérer dans les pages proviennent d’une analyse des pages que les moteurs remontent sur chacune de vos requêtes. Mais tout repose sur l’analyse !
Exemple :
Vous avez une page dont la requête principale (requête que vous pensez être la plus pertinente pour cette page) est « recette indienne de tofu pimenté ». Un logiciel va aller analyser le contenu des 100 pages qui remontent sur cette requête « recette indienne de tofu pimenté ».
Plusieurs types d’analyses sont possibles et toutes n’utilisent pas les mêmes algorithmes. Les cooccurrences, champs lexicaux (et synonymes) permettent juste de vous donner des idées pour enrichir vos contenus, rien de plus. Il est possible, par contre, que cet enrichissement apporte un plus en positionnement par effet de bord, mais ce n’est jamais certain. C’est un peu « au petit bonheur la chance »…
Les metamots sont très différents et reposent entièrement sur le pageRank thématique.
Expliquons-nous.
Déjà, on va éliminer ce que les metamots ne sont pas :
- Les metamots ne sont pas des champs lexicaux, au sens réel du terme, à savoir des mots dont le sens est déterminé par le lexique (par opposition à la grammaire).
- Les metamots ne sont pas des cooccurrences, du moins pas que et pas forcément (les cooccurrences sont, par erreur, parfois appelées des champs lexicaux, passons…).
- Et bien sûr, les metamots n’ont rien à voir avec des synonymes… (!!)
Les metamots forment une empreinte permettant à des moteurs d’identifier que votre page est pertinente à se positionner sur une requête précise. Cela n’est pas un critère de pertinence, mais un critère de confiance.
Un metamot est formé de plusieurs lexies. Ce sont ces lexies, mises ENSEMBLE, qui constituent l’empreinte.
Même si les metamots ne constituent pas en eux-mêmes une action, ils valorisent fortement les actions que vous faites. Si vous ne faites rien, il ne se passera peut-être pas grand-chose, mais si vous vous servez des metamots au sein de vos actions (SEO, contenu, cocon sémantique, etc.), cela peut vous changer la donne du tout au tout !
Voici un exemple imagé pour compléter :
Luc pose une question à Yoda
Yoda lui répond : « Attendre pour savoir tu dois »
Quelques jours après, Luc repose sa question à Yoda :
Yoda lui répond : « Attendre pour savoir tu dois »
Un mois passe et Luc retente sa chance :
Yoda lui répond encore : « Attendre pour savoir tu dois »
Après plusieurs autres tentatives, Luc obtient enfin sa réponse et Yoda de lui dire :
« Ce que tu observes n’existe que si le temps existe ».
- Le système de cooccurrences va vous dire d’ajouter dans votre page « Attendre pour savoir tu dois » (car cela a beaucoup été répété).
- Les champs lexicaux : « Le savoir prend du temps pour être acquis ».
- Les metamots : « Ce que tu observes n’existe que si le temps existe ». Pourquoi ? Parce que c’est cette réponse qui est importante.
2) Début de preuve de l’existence des metamots
Est-ce que les metamots sont une coïncidence ou une empreinte bien réelle ?
Pour avoir un début de preuve, factuelle et sans délire, on peut faire une vérification des metamots en mode « échantillonnage croisé ». C’est plus parlant que des maths.
Prenons 100 résultats de GG sur une requête prise au hasard. On fait deux paquets. Un avec les pages en pos 1, 3, 5… 99 de la SERP et un autre paquet avec les pages 2, 4, 6 … 100.
Calculons les metamots de ces deux paquets. Curieusement, on a les mêmes metamots (à 95-96 %).
Concluez ;-).
3) Quels sens ont les valeurs en face de chaque lexie dans les metamots ?
J’appelle cela l’attirance qu’exerce le corpus sur chacune des lexies.On peut l’expliquer avec un autre point de vue : c’est la probalité x précision x certitude x environnement x confiance x autorité , avec quelques autres sucreries.
Ici et un peu là, je parle de logique floue. Nous sommes en plein dedans !
4) Metamots en mode passif et mode actif
Pour réaliser un cocon sémantique avec les metamots, on peut soit élaborer son cocon comme on le fait d’habitude (voir la formation de Laurent Bourrelly sur les cocons sémantiques), puis trouver les mots-clés des pages du cocon, et enfin injecter les metamots. C’est ici ce que je nomme le mode passif (sans que cela ne soit péjoratif).On peut aussi, et surtout, demander aux metamots de vous construire l’arborescence du cocon sémantique. C’est le mode actif.
C’est en mode actif que nous allons élaborer notre cocon pour aider Laurent à être prem’s sur VTT.
5) Le principe
Je vais calculer plein de metamots, à la fois sur des requêtes proches de VTT, mais je vais aussi voir ce que je peux faire avec l’ami wikipedia qui me semble être ici un bon complément.Dans d’autres cas, j’utiliserai comme complément des sites institutionnels, des forums, c’est un peu comme je le sens.
Ça, c’est juste pour initialiser le système, le jus sémantique étant éventuellement ailleurs…
Je vais donc avoir plein de requêtes et plein de metamots et c’est dans ce magma de possibilités que le logiciel va aller choisir le meilleur cocon possible avec comme priorité d’avoir le meilleur glissement sémantique possible.
Certes, cela va peut-être me faire calculer 900 metamots pour deux cocons sémantiques de 340 et 780 pages, mais je cherche l’or, pas le bronze ;-).
Note : même si on a une arborescence énorme, on n’est pas obligé de monter toutes les branches en une fois. Peut-être qu’au bout de 50 pages de cocon on sera premier sur « VTT » et il sera inutile d’aller plus loin.
6) Étape 1
N’oublions pas, je n’ai qu’un seul terme « VTT ». Laurent m’a dit : « Démerde-toi, je suis le client, je n’ai pas de temps à consacrer à une recherche de mots-clés et de sujets de pages ».Je vais dans yooda insight (quelle idée une appellation anglo-saxone pour une base de mots en français !).
Je demande à Yoodi-Yooda de me donner des idées de mots-clés sur la base de ma requête cible : « VTT ».
Yooda me donne 173 mots-clés. Ok, je les prends tous, à ce stade, pas de questions à se poser, je prends tout ce que je trouve.
En parallèle, je vais dans Wikipedia où je récupère les suggestions de recherche sur « VTT ».

Je récupère aussi le sommaire de la page principale de VTT.
J’ai quelques noms de champions du Monde dans cette page, et quelques noms de course, ça peut servir, allez on récupère aussi.
Je ne fais pas de sélection à ce stade, je prends tout. Wikipedia me donnent 120 termes à explorer.
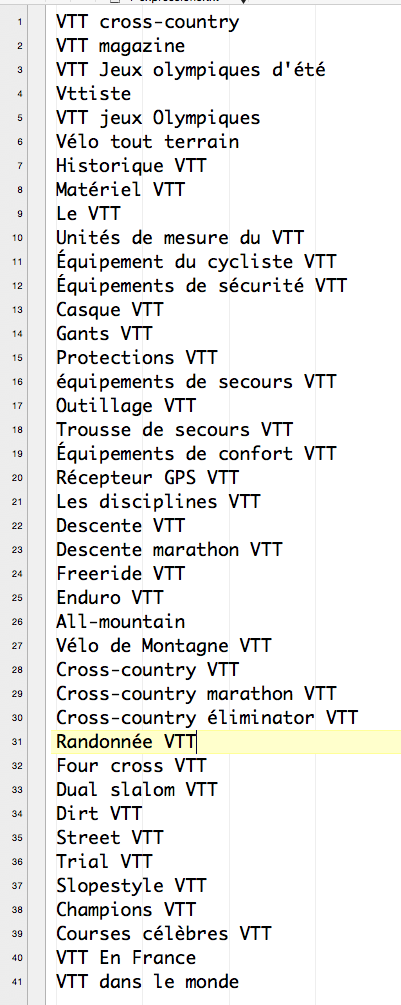
J’en arrive donc à 293 metamots à calculer.
Je lance la « tâche 1 » : récupération de données et calculs des metamots sur les mots-clés suggérés par Yooda et par la page VTT de Wikitruc.
En parallèle, je lance une recherche spécifique sur Wikipedia pour les 120 termes qui étaient sur la page VTT de l’encyclopédie en ligne. Je lance la récupération de données et les calculs des metamots : « tâche 2 ».
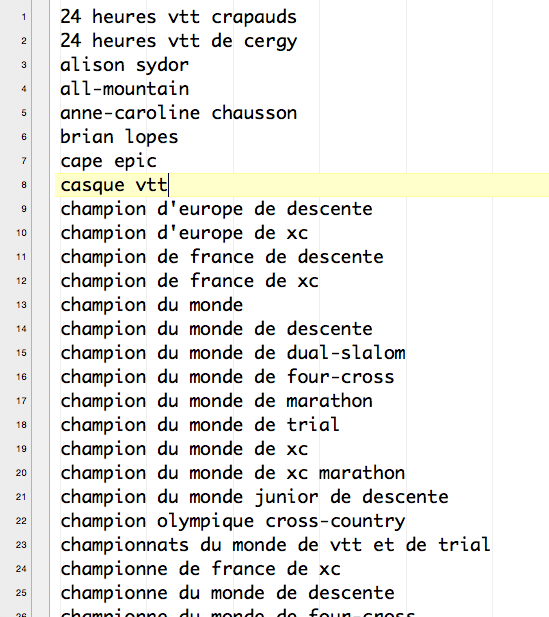
En résumé :
– tâche 1 : les requêtes suggérés par Yooda + celles provenant de wikipedia sont en cours de traitement (293)
– tâche 2 : les termes provenant de wikipedia sont traités une deuxième fois avec source de données wikipedia (120)
Je laisse tourner tout cela…
7) Étape 2
La « tâche 1 » est terminée.Le logiciel m’a non seulement créé le metamot pour chaque requête, mais aussi un metamot géant pour l’ensemble des requêtes.
Je vais aller analyser ce metamot géant car si des termes intéressants (associés forcément à VTT) se trouvent dedans, je sais que les pages que je trouverai ensuite seront en affinité sémantique forte avec les 293 premières requêtes/metamots/pages.
Note : j’ajoute presque toujours le terme vtt, pour que l’on reste bien dans la bonne thématique
Cela me donne 176 « requêtes » supplémentaires à aller examiner.
Notez que pour le moment, la « tâche 2 » tourne toujours et que je la laisse faire…
8) Étape 3
Je lance le calcul des metamots sur les 176 nouvelles requêtes : « tâche 3 »Une fois terminée, cela me fera 469 metamots (293 + 120 + 176)…
Il ne faut pas hésiter à y aller fort, VTT est tapé plus de 60.000 fois par mois le jour de la rédaction de ce billet, il faut se donner les moyens d’aller chercher cette requête.
De toute façon, la quantité de metamots calculés n’est pas la taille du cocon sémantique.
En effet, c’est le logiciel qui choisira lui-même quoi placer dans le cocon en fonction de la taille choisie. En d’autres termes, il faut que l’on ait au minimum autant de metamots que de pages dans le cocon mais c’est nettement mieux d’avoir plus de metamots que nécessaire : le logiciel aura de quoi choisir la meilleure combinaison ;-).
—-
ça tourne…
9) Étape 4
Bon… et wikipedia, il y en est où bonhomme ? (vous savez, la « tâche 2 »)C’est bon. Ce qui est bien avec wikipedia, c’est que l’analyse de son metamot géant révèle des requêtes de formes souvent un peu différentes, et même parfois de vrais sujets directement utilisables.
Je ne me servirai pas de ces metamots directement dans le cocon car ils viennent ici de Wikipedia mais je vais voir quels sujets il m’a trouvé via l’analyse du metamot géant-wikipédié, ça, ça m’intéresse…
514 propositions issues de l’analyse wikipedia… mais certaines étaient dans l’autre lot.
Je lance aussi une analyse du metamot-géant GG : 398 propositions.
Je dédoublonne le tout ainsi qu’avec ce que j’ai déjà traité, il me reste 438 nouvelles requêtes à explorer.
Et hop, « tâche 4 » in progress…
10) Le cocon sémantique est avancé !
Je dispose maintenant de 892 metamots. Je vais demander au logiciel de me trouver les deux meilleures arborescences possible, une de 340 pages et une autre de 780.Le logiciel va utiliser ses petites mains à lui pour trouver les meilleurs glissements sémantiques possible, basés sur ce que connait Google.
Car c’est bien là qu’est la force du système : on ne cherche pas à ajouter des mots communs à plusieurs pages pour assurer un glissement hasardeux, mais on construit une arborescence fondée sur les glissements sémantiques entre metamots.
Je vous ai mis plus bas le résultat, avec deux MindMap au format .mm s’ouvrant dans FreeMind et pouvant s’importer dans xMind.
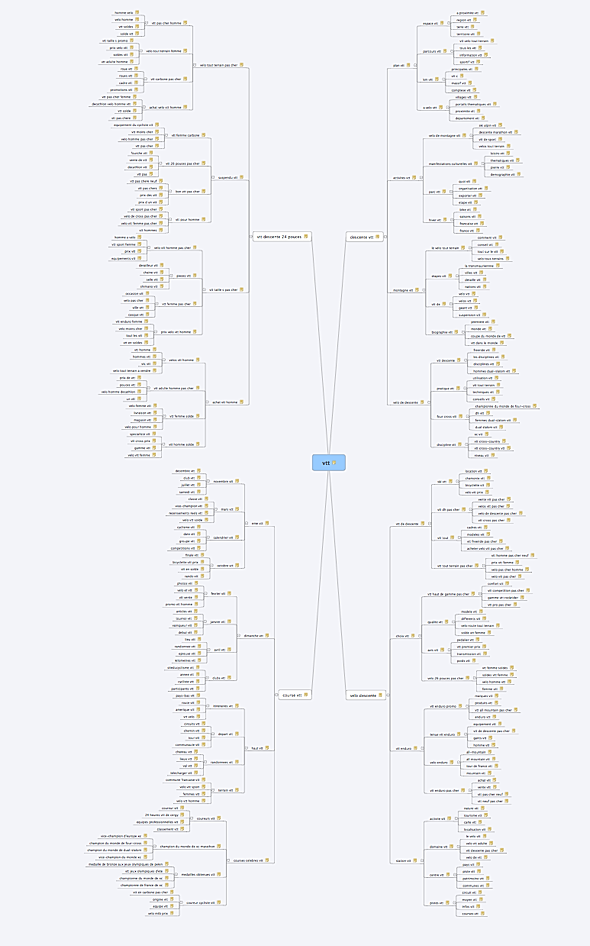
Ici, le plus petit des deux cocons sémantiques, 340 noeuds…
Dans les notes de chaque page, vous avez les instructions pour chacune des pages… ensuite, vous pouvez importer cela dans WordPress via bombyx.
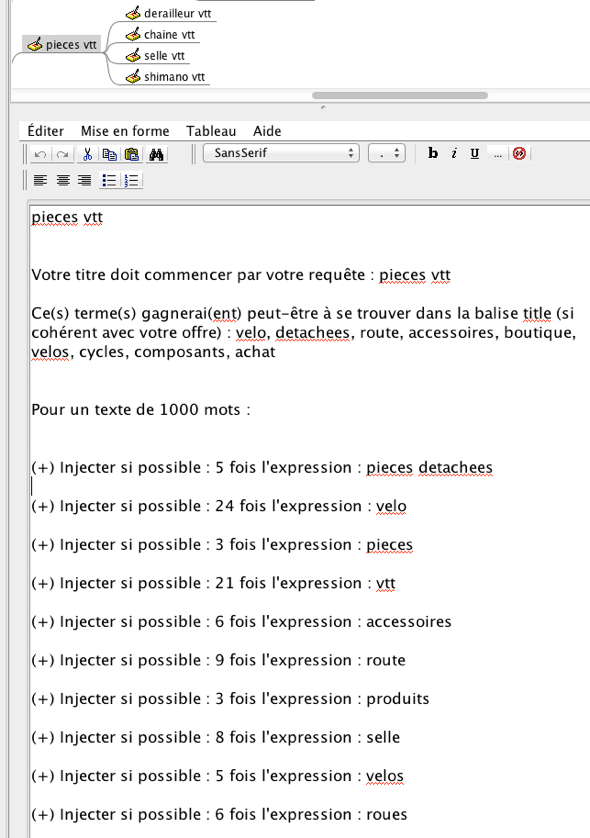
Le rédacteur devra être parfois un peu imaginatif pour entrer dans le moule, mais ensuite, quel plaisir !
Les nombres de fois où les mots devraient être répétés sont indicatifs, ne bourrinez pas trop 😉 .
Note : beaucoup de cocons n’ont pas besoin d’être aussi gros, mais, c’était amusant de construire une arborescence de mega-cocon sémantique ;-).
11) Liens connexes
Visiblis, un gars très sympa avec un chapôCocon.se, la G-Rafh, pour passer d’un site à un dessin déjà colorié ;-).
Mes remerciements aussi à Camille qui, avec son billet, m’a permis d’identifier certains lacunes de mes explications précédentes.
Vous l’avez mérité : si vous êtes arrivé ici, il est là
Mots-clefs : cocon sémantique, glissements sémantiques, metamot
Camille
| #
Pfiou !
Alors en plus d’avoir une explication plus accessible (mais heureusement que vous m’aviez bien débroussaillé le début avant, quand même), tu présentes vraiment bien par l’application le principe.
Ce qui aide grandement (je trouve) dans l’explication. Alors, j’en profite, reprenons ce que je pense avoir compris ici :
Empreinte > Meta-mots > Lexies
cooccurrences : C’est en gros tout ce que l’on retrouve fréquemment dans la thématique (ici, la discussion ?)
Champ lexical : L’idée globale (ou le chant sémantique ?) que l’on peut trouver dans la thématique.
Meta-mots : Les mots composant la réponse pertinente à la requête…? (si je reprends l’exemple)
Apparemment, un logiciel est quand même souhaitable pour faire ça bien… J’ai assez peu l’impression qu’un être humain pourrait s’en charger sans y passer des plombes, et y perdre en justesse.
En fait, à force de lire ce concept, une question me chiffonne : pourquoi diable est-ce qu’on n’en parle pas plus aux rédacs ? Ça semble méchamment important à comprendre, non ? Est-ce parce que, théoriquement, ils ont leur liste toute prête de mots à employer ?
Bref, merci une nouvelle fois d’avoir pris ce temps précieux. Je m’empresse d’ajouter ton article au mien, j’ai déjà eu le retour d’une Rédactrice qui a été surprise et intéressée d’apprendre ce principe, et qui, du coup, a eut envie de te lire 😀
Reply
Christian Méline
| #
Pour ma part, j’en parle en conférence, mais c’est un résultat de R&D personnelle et je ne fais pas trop de tapage là-dessus…
Reply
ArthanSEO
| #
L’article précédent était déjà assez limpide. Là l’exemple + l’adaptation au cocon sémantique met clairement les points sur les i
Pour un cocon ultra bourrin comme ça, le temps de calcul est à combien (à la louche) ?
Reply
Christian Méline
| #
J’ai une connexion internet assez minable (2MB) donc je suis limité à 400 meta-mots en quelques heures. Par contre, quand ce sont des pdfs (que j’analyse aussi), c’est plus lent. La médecine par exemple est longue à analyser…
Pour la partie calcul, un meta-mot sur la base de 100 pages, met moins de 45 secondes.
Reply
Laurent Bourrelly
| #
Bon ben il ne me reste plus qu’à me mettre au boulot pour relever le défi 😉
Christian vous en dis plus que d’habitude et surtout fais une belle démo, mais je ne peux que vous conseiller vivement d’opter pour son kit de survie meta mots sur-mesure pour votre thématique.
Il a fait plein de liens vers toute la famille du cocon pascon (btw merci), mais il a oublié de mettre un CTA vers sa prestation.
Je certifie le meta mot 100% utile pour démarrer votre cocon sémantique par le bon bout.
Reply
Pascal_ccbb
| #
Top tes explications Christian. Mais il est ou le logiciel sas qui nous fait nos meta mots ? Idem pour cocon.se.
Reply
Christian Méline
| #
Merci 🙂
Le cas échant, ça peut être une micro-presta…
Reply
Mikael
| #
Merci pour cet article, j’ai presque tout compris ou pas ! 🙂
Reply
Denis
| #
Drôle et très bonne idée d’utiliser Wikipédia.
Reply
Patrick
| #
On se réjouit d’entendre ta conférence avec Laurent sur le sujet le 20 mai prochain 😉
Reply
Christian Méline
| #
Nous avons hâte d’y être ! 🙂
Reply
Christophe BENOIT
| #
C’est très clairement ce qui m’a incité à participer à cette journée. Au plaisir de vous y entendre.
Reply
Christian Méline
| #
merci 🙂
Reply
Seofred34
| #
Très intéressant. Sans dévoiler le secret professionnel, comment calcules-tu la structure optimales des arbres? Je me souviens de méthodes (dites de parcimonie) utilisées en systématique phylogénétique (tel le logiciel PAUP) pour établir les relations de parenté entre les espèces (à partir de différents critères) avec comme choix le plus court chemin. Je me demande si on ne pourrai pas croiser ces approches. Faut juste que je me replonge là dedans. Ce qui n’est pas une mince affaire.
Reply
Christian Méline
| #
C’est un calcul matriciel avec multiples itérations, mais avec des formules à moi…
L’ensemble converge vers le résultat qui, sur le papier, semble le meilleur globalement, mais en favorisant quelques endroits bien précis de l’arborescence… 😉
Pas sûr de t’avoir aider du coup !
Reply
Seofred34
| #
Plus ou moins 🙂 Merci en tout cas.
Reply
joel
| #
Super article. Il nous manque juste un élément clé : ton logiciel (ou feuille excel)…
Merci pour ces précisions.
Reply
Christian Méline
| #
Il faut appuyer sur le gros bouton rouge 😉
Reply
joel
| #
Je ne l’avais pas vu (ou ne voulais pas le voir) 😉
Bravo encore
Reply
martin
| #
Super l’article, merci pour les précisions.
Plus qu’à appliquer 🙂
Reply
Aurelien
| #
Hello Christian,
Merci pour ton article et le partage. Cela me rappelle ta bonne conf au tecknseo 🙂
Reply
Christian Méline
| #
Merci Aurélien,
Au Teknseo, j’introduisais aussi les intentions dans l’équation pour ajouter les glissements intentionnels.
Depuis, du coup, j’ai aussi intégré en entrée les personnas…
On montrera peut-être cela un jour. 😉
Reply
Thomas Cubel
| #
Super ton article Christian !
Plus lisible effectivement, ça se comprend mieux que certains de tes articles plus savants qui étaient à relire 10 ou 15 fois pour certains ahah.
Ta méthodologie est limpide et logique, on en a déjà parlé de nombreuses fois, mais ce que tu détiens là est une bonne approche pour comprendre ce que veux le moteur. Même si des questions comme « C’est efficace sur combien de temps ? » peuvent surgir, un sujet reste un sujet et tu t’en approcheras. Comme tu me l’as déjà dit, il suffit de recalculer 😉
Ce que j’espère par contre, c’est que cet effet ne va pas se perdre dans le temps. Google pourrait très bien te mettre des bâtons dans les roues s’il le voulait pour fausser un peu tout ça. Je pense que ça serait forcément au détriment de la pertinence, mais on en a vu des choses.
Un petit message pour les autres : achetez des méta mots à Christian, c’est super et il est super sympa !
A bientôt !
Thomas Cubel
Reply
Christian Méline
| #
Ce que veux le moteur est normalement aussi ce que veulent les internautes.
L’idée est d’aller dans le même sens que lui (et je ne suis pas hypocrite en +).
Pour rebondir sur ta question sur l’évolution, il faudra aussi un jour que j’aborde un sujet assez hard : les cocons mutants… une truc sacrément amusant 😉
Reply
Alexandre Santoni
| #
Bien, merci pour l’article et l’ensemble du procédé que tu utilises. A la louche, combien de temps pour arriver au résultat final que tu proposes aujourd’hui ? (tout compris, travaux + soft mais sans compter la R&D de départ bien entendu).
Bien envie de me lancer sur le sujet via un article aussi pour apporter quelques points complémentaire et différenciant. 😉
Reply
Christian Méline
| #
Je n’ai pas compté à vrai dire…
Par contre, comptes 45 secondes de calcul par meta-mot (je sais, ça fait rêver) et le calcul du cocon de 1000 nœuds met quelques minutes, mais je n’ai pas chronométré combien exactement (par contre, on n’est < x^2 en complexité, donc, l'augmentation de la quantité de meta-mots/noeuds n'impacte pas trop le temps de calcul du cocon). Le plus long, c'est la lecture des pages web et pdf, puisque j'ai une toute petite connexion (2MB, merci Orange de bien t'occuper des campagnes, hein).
Reply
David
| #
Bonjour Christian,
C’est ultra rare que je prenne la plume (le clavier en l’occurrence) mais vos articles sont réellement passionnant.
Maintenant je m’interroge un peu sur cette histoire de META MOTS car grosso modo, le travail consiste (en partie – je schématise hein !?) à « scanner » les 1xx pages présentes sur une requête dans le but d’en extraire le vocable / termes / mots, j’aurai donc un vocabulaire commun à mes 1xx pages de concurrents.
OK Google il va comprendre ce que je veux lui faire manger.
Mais je ne serai pas plus pertinent dans le fond que les 1xx autres, pourquoi google devrait me positionner moi en pole position ?
Aborder un lexique inédit de la totalité des concurrents ne jouerai pas justement sur un angle d’attaque différent pour aborder le sujet et donc susciter la curiosité de l’ami google ?
David
Reply
Christian Méline
| #
Le calcul consiste à extraire l’empreinte.
Personne ne l’utilise totalement dans les pages trouvées, il s’agit ici de la reconstituer et de l’utiliser 😉
Reply
David
| #
« Personne ne l’utilise totalement » => C’est sur que quand on rendre dans les détails, peu de sites sont vraiment totalement opti seo au final…
Donc en gros, je deviens « LA » référence sur le sujet de google en étant le seul à utiliser toute l’étendue du vocabulaire thématique, OK
Charge à moi au final de présenter ce vocabulaire dans un contenu qui tient la route et sur un format que peu n’utilisent : un blog si les 1xx premiers sont des e-commerces, … etc etc, un cocon par exemple ?!?
Si j’ai bon, j’ai enfin compris, merci :)… .
Reply
Sébastien
| #
Merci !
C’est un peu plus clair (bon je sens qu’il me faudra quand même relire les articles pour être bien sûr ^^).
Effectivement, sans le logiciel, cela parait compliqué à mettre en place.
Je serais curieux de voir le second cocon en tous cas !
Reply
Christian Méline
| #
Le deux cocons sont dans l’archive.
Reply
Sébastien
| #
Effectivement je viens de voir ça, je souhaite bon courage à Laurent Bourrelly en tous cas !
Reply
Christian Méline
| #
Il veut être prem’s 😀
Reply
mickael
| #
Bonjour Christian,
Merci pour cet article limpide. Une question qui n’a pas de rapport directement avec les meta mots mais plus avec le cocon me turlupine. Dans les 2 cocons que tu donne en exemple en sortie de ton logiciel, 340 ou 780 pages chaque cocon a respectivement 4 ou 5 filles à chaque mère. Pourquoi cette rigueur ou automatisme?
Reply
Christian Méline
| #
Bonjour Mickaël,
C’est souvent assez efficace (circulation du jus)
Reply
Denis
| #
La seule chose que j’ai beaucoup de mal à percevoir, c’est la manière d’établir les « hiérarchies » sémantiques !
Reply
Christian Méline
| #
Avec ce que l’on a dans les meta-mots, on peut facilement gérer les distances sémantiques, et donc, créer des arbres, etc.
En plus, c’est amusant 🙂
Reply
Teddy
| #
Hello Christian,
Ok pour l’explication mais je ne sais pas si c’est moi, j’ai l’impression que tu compliques un peu trop la chose 🙂 Sans remettre en cause ton analyse bien sur.
Mais en fait je pense qu’on pourrait arriver au même résultats de méta-mots en utilisant une matrice sémantique + un scrap approfondi Google Suggest. Ensuite il faut encore construire le cocon à la main (je n’ai pas encore trouvé de formule magique pour allez vite je l’avoue).
En tous cas merci pour le cadeau (ca permet de comparer les méthodes de chacun). Comme Laurent disais tu aurais du marketer un peu plus ton billet avec un CTA et un catcheur d’email pour télécharger le cocon ^^
En tous cas impressionnant le résultat final, encore bravo !
Reply
Christian Méline
| #
Bonsoir Teddy,
Par sûr que l’on arrive aux mêmes résultats…
J’arrive à faire de la classification avec ce système, en partant de Google; du coup, les cocons sont naturels avec ce que lui est capable de capter.
Pourtant, je n’irai pas dire que GG fait de la sémantique. Il a plutôt une sorte de système d’écoute du web, ce qui est assez différent…
Oui, pour le CTA, mails, etc. mais bon, c’est aussi du partage !
Merci d’avoir apprécier le job en tous les cas 🙂 .
Reply
Ropo
| #
Merci pour la vulgarisation Christian , par contre lorsque l’on dit « enfin » un article compréhensible moi pas être d’accord ! j’ai toujours beaucoup aimé le ton et style de tes articles en général, ça permet de se creuser un peu la tête de façon ludique en lisant un article SEO 🙂
Reply
Christian Méline
| #
Ne t’inquiètes pas, je n’ai pas dit mon dernier mot ! 😉
Reply
Chouchou Et Loulou, les flammes jumelles
| #
Très intéressant cet article, merci pour le partage. Ce qui est appréciable, c’est le côté concret. Un bon dossier sur l’importance de la sémantique. Wikipédia reste une référence. Pourtant, il n’a pas réinventé la roue, il a simplement un énorme thésaurus, un maillage interne à gogo, une structure et arborescence parfaite, et un temps de chargement difficilement comparable. Il se concentre sur le contenu. Idéal pour Google pour comprendre le sens de la thématique.
Reply
Christian Méline
| #
Sur l’arborescence de wikipedia, c’est pas sûr…. en fouillant beaucoup leurs arbos, on trouve une redondance énorme avec parfois plus de catégories que d’articles… parfois dupliqués entre eux !
Sinon, GG a avoué avoir fait des calculs en partant de wikipedia…
Merci d’avoir apprécié le billet 🙂
Reply
Laurence
| #
Bonjour Christian,
Article tres interessant, j’ai hate d’etre a vendredi pour l’introduction si longtemps attendue!
A tres bientot.
Reply
Christian Méline
| #
ce d’autant que la version anglaise n’est plus très loin 🙂
Reply
Jojo le pirae
| #
Bonjour et merci pour cet article d’un niveau + élevé que ce qu’on à l’habitude de lire 🙂
J’ai une simple question sur le cocon sémantique (un peu HS oui).
Si tout le site est en silo (index => catégorie => sous-catégorie => articles =>maillage interne vers tags)
Donc un silo assez basique et ce qu’il y a de + normal, perd t-on la force du cocon si on a UNE page répertoriant toutes les catégories et sous-catégories et même quelques tags… ?
Serait t’il judicieux de mettre cette page en no-index ? Ou alors uniquement tous les liens de cette page en nofollow ?
C’est une grosse question que je me pose depuis un bon bout de temps mais j’ai aucun moyen de tester ça. J’ai ce système en place sur un très gros site et j’hésite à renforcer encore + l’effet silo en mettant cette fameuse page en nofollow sur tous les liens qu’elle contient.
Merci pour ton avis sur la question si tu as ton idée.
Reply
Christian Méline
| #
Le nofollow est la NÉGATION du web. C’est un crime qu’a commis GG en introduisant cet attribut.
J’ai mon idée sur la question, puisque l’on se sert aussi des meta-mots pour construire les rubriques de site e-commerce.
Mais ce ne pourra pas être une réponse dans un commentaire, c’est trop long à expliquer.
Reply
Jérôme
| #
@Christian, le « gars très sympa avec un chapô » il te dit … Chapô bas pour cet article. C’est précis, concret, didactique et complet, du bel ouvrage comme on dit.
Tu aurais pu intituler ton article « META-mots ou la METAmorphose du cocon sémantique » 😉
Maintenant, l’étape suivante, c’est de générer automatiquement les textes des pages à partir des nombres d’occurrences des mots…
Reply
Christian Méline
| #
Merci Jérôme 🙂
Pour les textes, on le fait déjà (en R&D), mais c’est laid et cela tache mon poil blanc 😉
Reply
Jérôme
| #
On en causera en privé, car de mon côté c’est pas trop moche
Reply
Christian Méline
| #
C’est la démarche surtout… 😉
Reply
SEO : respirez le mot clef
| #
[…] Sur une note plus positive, vous ne pouvez pas avoir loupé l’exceptionnel billet de @ChristianMeline sur le meta mot appliqué au cocon sémantique. […]
Reply
Kristof
| #
Sans remettre en cause l’efficacité et la pertinence de l’outil, cette hyper rationalisation de l architecture ne laisse pas beaucoup de place à la poésie dites-moi. Ne va-t-on pas vers une standardisation des architectures et des contenus, que faites vous par exemple si 5 concurrents vous passent commande du même mot-clé ?
Cela dit, il reste à rédiger…
Merci pour la clarté des explications, c’est très vendeur.
Reply
Christian Méline
| #
Le problème de clients qui pourraient être directement concurrents se pose depuis que la communication, le marketing, la publicité et le SEO existent.
Pour ma part, je prends le premier et pas le deuxième, sauf à distance dans le temps.
Ensuite, par rapport aux cocons, la probabilité d’avoir exactement le même mot-clé reste faible.
Reply
Veronica Infante
| #
Bonjour, Merci pour cet article très instructif et très intéressant. Ca améliore mes connaissances et je crois avoir tout compris… ou peut être pas! 🙂 J’ai appuyé sur le bouton rouge, question: est-ce qu’il est possible de faire avec moins de 100 méta mots?
Reply
Christian Méline
| #
Bonjour, à partir de 50 meta-mots on fait des choses sympas 😉
Reply
Nicolas
| #
O_O <= j'ai fait une tête dans ce genre à la fin de l'article.
Cet article est super Christian, précis et l’application au cocon est tout bonnement logique.
Je n'ai trouvé si tu mettais à disposition ton outils ? (Ou alors je n'ai juste pas compris l'un des commentaires précédents)
Reply
Christian Méline
| #
Ce billet est un partage de mon quotidien; cela étant, il existe quand même un gros bouton rouge dans la sidebar 😉
Reply
PerformanceWeb, le 20 mai 2016, venez tisser des liens avec nous
| #
[…] y a quelques semaines est paru ici même un billet assez retentissant : « Réaliser un cocon sémantique avec les meta-mots »… Ce succès n’était pas prémédité et j’en suis moi-même surpris. Là où […]
Reply
White Staenk
| #
Merci pour ces explications limpides !
A quand la première page sur la requête VTT ?
🙂
Reply
Maximek
| #
Félicitations et merci pour la démo assez impressionnante, j’ai l’impression d’avoir bien tout compris sauf peut-être deux choses, quels logiciels utiliser pour récupérer les meta-mots et pour construire l’arborescence en cocons ?
Reply
Christian Méline
| #
Dans les deux cas, c’est le même logiciel : le mien.
Vas voir la page derrière le gros bouton rouge, en haut de la sidebar… 😉
Reply
Jean
| #
Très bon article !
Question subsidiaire : votre exemple utilise comme langue source le français. Effectuez-vous la même démarche dans le cadre de langues étrangères courantes (anglais, allemand…) et dans des langues plus « exotiques » (luxembourgeois par exemple) ?
Merci à vous
Reply
Christian Méline
| #
merci 🙂
Français et Anglais localisés pays par pays, y compris les pays d’Orient qui ont une version anglaise locale de GG…
Italien, Espagnol et Allemand vont suivre.
En fait, je peux monter à peu près n’importe quelle langue occidentale, c’est plus l’algorithme qui joue que les filtres en amont 😉 .
Reply
Liền kề gamuda
| #
Très bon article !
Question subsidiaire : votre exemple utilise comme langue source le français. Effectuez-vous la même démarche dans le cadre de langues étrangères courantes (anglais, allemand…) et dans des langues plus “exotiques” (luxembourgeois par exemple) ?
Reply
Christian Méline
| #
L’anglais est déjà disponibles pour 103 régions/pays dans le monde…
D’autres langues sont en préparation et, je l’espère, seront disponibles avant l’été. Certaines seront effectivement « exotiques » (dans le sens où vous utilisez ce mot.)
Reply